

140万亿词元调用量
相当于1000万亿个中文词汇
相当于250个国家图书馆资源量
中国日均词元调用量
2024年初1000亿
至2025年底100万亿
今年3月已突破140万亿
AI热潮中,一个概念的地位正在渐渐凸显——Token,它是排行榜上大模型调用量的评估标准,也是大模型厂商销售套餐的计费单位。
3月23日,在中国发展高层论坛2026年年会上,国家数据局局长刘烈宏表示,Token“词元”不仅是智能时代的价值锚点,更是连接技术供给与商业需求的“结算单位”,为商业模式的落地提供了可量化的可能。
这给出了Token的中文翻译:“词元”。
词元 Token
是大模型处理信息的最小信息单元,具有智能时代可计量、可定价、可交易的特征。当下,围绕词元的调用、分发与结算,一套新的价值体系正在加速演进形成,并成为人工智能产业商业化的重要路径。
新的价值体系加速演进形成
企业用多少词元付多少费用
人民日报记者从国家数据局获悉:2024年初,中国日均词元(Token)调用量为1000亿;至2025年底,跃升至100万亿;今年3月,已突破140万亿,两年增长超千倍。
刘烈宏指出,今年1月底以来,有的模型企业创下20天收入超越2025年全年总收入的业绩纪录。这组数字背后,是一套以Token计费为基础的新型商业逻辑正在加速演进。
我国日均词元调用量的大幅增长也表明,随着数据要素市场化配置改革的纵深推进,人工智能高质量数据的供给体系正在形成,“数据供给—价值释放”的良性循环初显。
“词元”是人工智能大模型为了高效处理数据,把数据进行拆分后的最小信息单元,可以理解为一个字,或是一个词,或是一个符号。在人工智能时代,用户输入的每一个字,大模型生成的每一段话、识别的每一幅图像,都在消耗词元。
国家数据局专家咨询委员会委员张向宏介绍,日均超140万亿的词元调用量,相当于1000万亿个中文词汇,也相当于250个中国国家图书馆的资源量。
国家发展改革委国家信息中心人工智能处工程师蔡驰宇介绍,词元日均调用量大幅增长,充分表明人工智能正加速从实验室走向千行百业和千家万户,变成了实实在在的生产力工具,像水、电、网络一样,成为智能社会运转的基础资源。词元的消耗量是人工智能产业发展的重要指标和“晴雨表”。
围绕词元的调用、分发与结算,一套新的价值体系正在加速演进形成,并成为人工智能产业可能变现的重要路径。
蔡驰宇介绍,过去,一家企业使用信息服务,需要购买信息软件;现在一家企业使用信息服务,可能直接调用大模型接口,用多少词元,就付多少费用,以词元消耗量的多少作为计费依据。
与此同时,专家表示,词元消耗量增长也对电力资源提出了更高需求。今年的《政府工作报告》提出,实施算电协同等新基建工程。专家介绍,算电协同的本质含义,就是要使用我国具有超前优势的绿电来发展算力产业和人工智能产业。
AI的“翻译员”
解密一个词元的神秘旅程
每次与人工智能对话时,你有没有好奇过:冰冷的数据如何变成鲜活、智能的内容?要搞懂这背后的门道,得先了解词元是如何“流动”的。
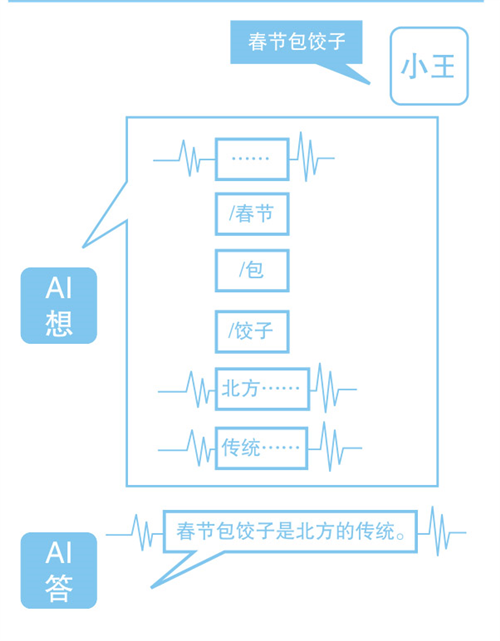
对人工智能来说,词元就像一位“翻译员”,在人类语言和机器数字之间搭起桥梁。所有喂给人工智能的数据,都需要先按规则切分成独立的词元,再转换为数字编码,才能被人工智能识别。比如你输入“春节包饺子”,人工智能会切分为“春节/包/饺子”三个词元,再从“字典”中找到匹配的编码。
要想大规模批量处理这些词元,离不开一座“词元工厂”——数据中心。人工智能正式上岗前,需要经历一个训练的过程:数据中心消耗大量电力,开动算力引擎,把数十万亿级的词元源源不断地喂给人工智能。它要做的是挖掘并记住词元间的关联关系,比如当“春节/包/饺子”出现时,人工智能就能联想到在学习材料中常与它们同框出现的“北方”和“传统”等词元。这些从海量词元中沉淀下来的经验,就是我们感知到的“智能”。
等到你向人工智能提问时,工厂再次运转。问题被切分成词元送给人工智能,庞大的算力群随即驱动它进行一场“文字接龙”,也就是推理。人工智能根据输入的词元,依据之前学到的经验规律,逐次预测下一个最可能出现的词元,一步步拼接出完整内容,再翻译回人类文字,于是屏幕上便跃出那句:“春节包饺子是北方的传统。”
跳动的词元背后是生产力的跃迁,使得人工智能可以从海量的数据中发现其中深层的关联规律,极大地拓展了数据价值挖掘的空间。也正是一个个小小的词元,串联起数据与智能的桥梁,不仅让数据拥有了温度,也让人工智能的每一次回应,都成为数据价值释放的生动实践。
本版整理 王永波
综合半月谈、人民日报、央视新闻
制图 苑靖
这届年轻人社交电量不足
“我的Token不够用了”
AI认为“无意义对话”
恰是人类最宝贵连接
“今天不想说话,我的Token不够用了!”这届年轻人的社交电量,都被谁偷走了?
词元“Token”,指AI处理文本的基本单位,也是计费和限制对话长度的依据。
这个大模型处理信息的最小信息单元,越来越多地被应用在社交关系上。譬如,“我的Token不够用了”,从职场角度可以解释为“我今天累了”,或延伸为“我不想说话了”“请不要打扰我”,以此轻柔退出。在“Token”概念框架的泛化下,我们的社交“语料库”似乎愈发丰富,诸如“我的分布式算力已不足”“假期余额需要续费或升级套餐”“你给我发的这个文件又消耗了我10KB流量”等诙谐说法层出不穷。
当下,不少人被技术浪潮裹挟,互相比拼谁消耗的Token更多。在工作效率大大提升的同时,越来越多的人面临着“AI疲惫”,包括付出更多的情绪劳动和注意力资源。
一则帖子引起不少网友共鸣:“在AI诞生之前,人类很少意识到自身词元(Token)的宝贵。”个体的注意力、表达欲和情绪承载力,都是会被消耗的重要资源。人并不是一个固定额度系统,而是更像一段会呼吸的代码,会产生波动,会扩展,如果不加节制地使用,也会濒临枯竭。现实生活中,人们需要在静思中恢复,在被理解时增长,在爱与表达中重新生成。
如果一切都按照调用的Token量和效率来衡量,人生就容易异化为一套精密而缺乏温度的程序系统。事实上,家人间的“无意义对话”、朋友间的相知与陪伴,是“明知会消耗却仍然愿意给予自身精力的温暖瞬间”。在Token的视野下,这些都是浪费,而在人类的世界中,这些是连接。
AI狂奔,就连形容人类关系的辞藻都充满“机器味”。我们更需珍视那些不被优化、不受计算的真实关系,它们缓慢、质朴又真切。当我们挡不住“AI疲惫”来袭时,是否也该反思:人与AI的边界在哪里,我的宝贵的Token该如何恢复与增长?
